Capítulo 11 Modelo para Leach Pads
Este capítulo guiará al usuario a través del módulo Modelo de leach pads que ofrece Opencontour. Esto incluye la configuración de un nuevo modelo, la ejecución del modelo, y varias propiedades y funciones que están asociadas con la característica en sí. Esta sección también explicará cómo combinar datos históricos para realizar previsiones.
Acceso Rápido
- Resumen General
- Configuración de un nuevo modelo de recuperación de leach pads
- Preparar y ejecutar el modelo de recuperación de lixiviación en leach pad
- Modelo de recuperación de leach pad
- Ejecución del modelo de recuperación de lixiviación en leach pad
- Uso de la función Write State y lectura para modelos más grandes
- Combinación de datos históricos con actualizaciones futuras (pronóstico)
- Propiedades del modelo de recuperación CutterResult
- Funciones Agregadas y Resultados del Modelo de Recuperación
11.1 Resumen General
Antes de empezar el modelo de recuperación en leach pads (Modelo HPL), Opencontour recomienda al usuario seguir algunos pasos para permitir que el modelo se ejecute sin contratiempos significativos. Es importante destacar que el Modelo HPL se ejecuta después de haber actualizado y guardado el Plan de Apilamiento histórico y/o previsto.
Esta guía del usuario asume que el usuario tendrá la configuración del proyecto más actualizada, con toda la información de apilamiento del proyecto.
Para obtener más información sobre la configuración del proyecto y las propiedades del proyecto, consulte el Capítulo 3.
Al configurar un modelo HPL, es importante resaltar las propiedades que deberán revisarse y actualizarse si es necesario. Asegúrese de seleccionar su unidad de medida, métrica o imperial. Opencontour rellenará previamente la mayoría de estos campos con datos estándar de la industria. Asegúrese de actualizar la densidad utilizada para su proyecto. Además, asegúrese de que el valor 'Oleaje volumétrico' para el proyecto esté establecido en 1.
Altura del banco (Bench Height): Opencontour discretiza a la altura del banco. Por lo tanto, al seleccionar la altura del banco las propiedades del proyecto, la altura de discretización se establece automáticamente en el mismo valor.
NOTA: la altura del banco suele ser una fracción de la altura de elevación. Por ejemplo, una altura de elevación de 10 m puede tener una altura de banco de 2 m.
11.2 Configuración de un nuevo modelo de recuperación de leach pads
11.2.1 Nuevo proyecto
Crear un nuevo proyecto importando la configuración del proyecto, incluida la información de apilamiento más actualizada. Comience arrastrando y soltando su archivo '_all.json' en la ventana del proyecto. Vaya a la elevación adecuada para ver la capa base; puede usar Q o W, actualizar la elevación en la sección banco (Bench) de configuración de la vista del proyecto, presionar Enter o Ejecutar (Run).
Ahora puede ver todas las capas de relleno usados para crear el plan de apilamiento. Utilizamos estas capas de relleno para hacer los levantamientos, todo dentro de su capa base (siempre resaltado en rojo).
11.2.2 Prácticas recomendadas
Antes de empezar a trabajar en el modelo de recuperación HLP, le recomendamos que siga estos pasos:
- En el menú de herramientas, seleccione el módulo Heap Leach Stacking. Antes de que el usuario pueda ejecutar el modelo, todos los iconos de progreso tendrán que tener una marca de verificación verde; para revisar el proceso de apilamiento de leach pads y como llegar a este punto en el proceso, por favor revise el Capítulo 6.
- Marque la casilla "For Model" (para el modelo) de la ventana de progreso y haga clic en Discretizar; esto dividirá todas las contornos en bloques completos para que se ajusten al modelo.
- El siguiente paso es importar su plan de minado a través de un formato CSV o 'model.json'. Una vez hecho esto, se le pedirá que rellene el Mineplan. Esto esencialmente dividirá el plan de mina en pequeños bloques que se ajustarán al modelo creado cuando los datos fueron discretizados. Recuerde que el Modelo asignará automáticamente un ltp (tipo de lixiviación) de 1 a las propiedades del Mineplan. Si está buscando tener múltiples designaciones ltp, abra el menú de la utilidad de scripts y agregue/edite scripts.
Ahora que estamos seguros de que nuestro Plan de apilamiento está en su lugar y toda la información necesaria para ejecutar el modelo se ha actualizado, podemos preparar y ejecutar el modelo de recuperación de leach pads.
11.3 Preparar y ejecutar el modelo de recuperación de lixiviación en leach pad
Algunos proyectos requerirán el uso de figuras de solución; si este es el caso de su proyecto, revise los siguientes pasos; de lo contrario, continúe con el paso 7.4.
11.3.1 Si las celdas de solución ya existen en el plan de apilamiento
Active la capa de solución (solution layer) (que se volverá naranja) y seleccione el ciclo en el que desea ver las celdas, por ejemplo, todo. Haga clic en la ventana del proyecto y suba o baje la elevación para ver las celdas (Q o W).
11.3.2 Adición de solución al modelo
- Cree sus propias formas de solución:
- Seleccione Agregar capa (Add Layer) y, a continuación, Agregue capa de solución (Solution Layer)
- Asegúrese de que la capa de solución este seleccionada, seleccione la herramienta Agregar polígono
 en la barra de herramientas y dibuje la el polígono de la solución. Asegúrese de hacer doble clic cuando la forma esté terminada; esto creará la forma y proporcionará propiedades como la fecha de inicio y el periodo lt (días).
en la barra de herramientas y dibuje la el polígono de la solución. Asegúrese de hacer doble clic cuando la forma esté terminada; esto creará la forma y proporcionará propiedades como la fecha de inicio y el periodo lt (días). - Crear un script para aplicar propiedades de lixiviación a cada bloque de modelo
- En el menú de herramientas, seleccione Scripts y agregue scripts a cada propiedad. Hay scripts de solución simples dentro del menú desplegable repetitivo, pero se pueden crear scripts más complejos si es necesario.
Ahora que la información de la solución está en la capa menú, es importante actualizar la capa del modelo. Seleccione el botón Actualizar solución (Update Solution) del módulo Modelo de recuperación de lixiviación en pilas del menú de herramientas de la pestaña progreso. El usuario puede optar por Add BreakThrough Time en los polígonos de solución que existen en la capa de solución. Si el proyecto tiene bloques CutterResult que tienen propiedades on y lt escritas en ellos a través de un script, la solución actualizada (Update Solution) junto con la función Add BreakThrough Time anexará los días que tarde en pasar en función de las entradas globales del proyecto y la distancia al revestimiento.
Te recomendamos revisar los datos de la ratio de aplicación (App Rate) y el tiempo de lixiviación (Leach Time). Ratio de aplicación (App Rate) es el campo 'ar' en la tabla de la pestaña Solución en el menú Modelo de recuperación. El tiempo de lixiviación se detalla en la capa de solución.
Cuando se actualiza la solución, todas las celdas de CutterResult que tienen un on y lt y todas las celdas de soluciones se combinan y se escriben en la capa del modelo. Para ver las capas de solución creadas, active la capa de solución y haga clic en la clave "A". Ahora verá las formas de soluciones dentro del modelo.
11.3.3 Agregar una planta
Los proyectos de lixiviación en leach pad siempre tendrán una (1) planta donde se procesa la solución. Recomendamos agregar su(s) planta(s) en este punto del proceso de desarrollo del modelo.
Seleccione Herramienta de secuencia (Schedule tool) en la barra de herramientas y, a continuación, seleccione agregar elementos de planta (Plant Properties). El icono se volverá naranja cuando esté activo, luego haga clic en la ventana del proyecto (fuera de su cuadrícula), aparecerá la ventana Propiedades de la planta. Agregue tantas plantas como sea necesario y, a continuación, desactive la herramienta Programar de la barra de herramientas (volver a verde).
Una vez que se crea una planta, puede actualizar manualmente sus propiedades y cargar datos históricos (si corresponde) desde un archivo CSV.
Si el proyecto contiene flujos históricos bajos de barren y tenors, el usuario tiene la opción de cargar el archivo csv con todas las propiedades. Seleccione el icono planta / poza en su ventana de dibujo y haga clic para cargar un CSV. Aparecerá la ventana Propiedades, seleccione CSV y busque su archivo.
Consejo: vuelva a activar la capa Schedule para asegurarse de que el número de planos sea correcto. Si agregó más de lo necesario, seleccione la herramienta eliminar y elimine las que ya no necesite.
Opencontour establece por defecto el script model ltp en 1, sin embargo, recomendamos que el usuario revise los Model Scripts después de agregar uns planta(s) (Plant(s)). En el menú de herramientas, seleccione Script. El Software cargará por defecto las filas a las que se agregaron scripts durante la configuración del proyecto. Se recomienda que siempre carguemos scripts desde la fila 1 en adelante.
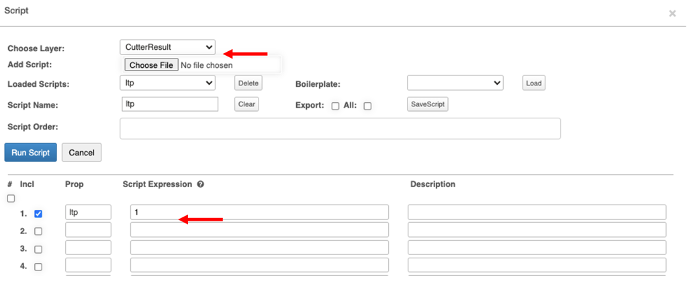
- Elija la capa → CutterResult
- Prop (Propiedades) → ltp(Tipo de lixiviación)
- Expresión de script → 1(Predeterminado)
- Si se agregaron más de una (1) propiedad ltp, actualice y ejecute (run) el script, y le pedirá información sobre cuántos scripts se calcularon. Haga clic en Aceptar. A continuación, cierre la ventana de script. De lo contrario, cierre la ventana.
11.3.4 Agregar un Poza
Seleccione la herramienta secuenciar (Schedule) en la barra de herramientas y, a continuación, agregar poza (add pond). De vuelta en su capa de solución, verá una nueva opción llamada "impermeable" (raincoat) seleccionada en el menú desplegable ciclo (cycle).
Seleccione Agregar polígono y dibuje el contorno; haga doble clic para crear el contorno y la lista Propiedades. Es importante que agregue propiedades y lt a su poza.
11.4 Modelo de recuperación de leach pad
En el menú de herramientas, seleccione Recuperación de lixiviación (Heap Leach Recovery); la siguiente ventana tendrá como valor predeterminado entradas (inputs). Se recomienda que revise y ajuste, si es necesario, el número de fechas para las que desea ejecutar el modelo. El número de días afectará la velocidad para ejecutar su modelo.
También recomendamos verificar sus entradas, especialmente si es la primera vez que ejecuta el modelo. Las entradas se cargaron como parte de la configuración del proyecto; sin embargo, estos se pueden actualizar manualmente. Recuerde guardar su proyecto con un nuevo nombre e informar a otros usuarios sobre los cambios (si usa los mismos archivos).
11.4.1 Entradas (Inputs)
Aquí, encontrará entradas estáticas de bloque a bloque (todos los bloques comparten estas propiedades) y entradas de control durante la duración del modelo.
Definiciones globales de inputs
| Entradas(Input) | Definición |
|---|---|
| Start | Fecha de inicio desde la que se ejecutará el modelo: tomada de la propiedad 'pm' más reciente colocado, no se requiere la entrada del usuario. |
| Run Duration | Duración en días en que se ejecutará el modelo. La actualización de la duración de la ejecución actualizará automáticamente la fecha de finalización.** |
| End | Fecha de finalización para la que se ejecutará el modelo. La actualización de la entrada final actualizará automáticamente la duración de la ejecución. |
| Time Step | El intervalo entre los cálculos del modelo, medido en días. Opencontour está configurado para que el paso de tiempo predeterminado sea 1, es decir, diario. |
- **Recomendamos ajustar el número de días para reflejar un período más corto a menos que el usuario requiera todos los datos a la vez.
Entradas Definiciones Operativas
| Entradas(Input) | Definición |
|---|---|
| Flowing Solutions Fraction | Un factor de calibración que representa el porcentaje de solución que se mueve entre bloques verticales. El 20% es el estándar probado en campo. La mayoría de los modelos de lixiviación no necesitarán ajustar este número. Opencontour/Forte puede proporcionar más definición e investigación si así lo solicita. |
| Mass Transfer Coefficient | Un factor de calibración que representa la velocidad a la que las partículas de oro se transfieren a la solución que fluye. 0.05 es el estándar probado en campo . La mayoría de los modelos de lixiviación no necesitarán ajustar este número. Opencontour/Forte puede proporcionar más definición e investigación si así lo solicita. |
| Dry Ore Bulk Density | Densidad de cada bloque de resultados de corte. |
| Leach Capacity | El contenido de humedad gravimétrica en estado estacionario cuando el mineral está siendo lixiviado, basado en datos de laboratorio y cálculo de la metodología de lixiviación en pilas para flujos insaturados. Esto puede ser proporcionado por Forte basado en el análisis de datos de laboratorio y otras propiedades del mineral. |
| Field Capacity | El contenido de humedad gravimétrica residual, basado en datos de laboratorio. Por lo general, se encuentra a partir de pruebas de permeabilidad compactadas. |
Definiciones de Parámetros de Grid
| Entradas(Input) | Definición |
|---|---|
| Width | Ancho de cada celda |
| Length | Altura de cada celda |
| Area | Área de cada celda |
Retraso de Extracción por Profundidad
| Entradas(Input) | Definición |
|---|---|
| Cut Point | El factor científico que simula el retraso de extracción por profundidad. 300 pies o 100 metros es el estándar probado en campo . La mayoría de los modelos de lixiviación no necesitarán ajustar este número. Opencontour/Forte puede proporcionar más definición e investigación si así lo solicita. |
| Slope | Factor científico que simula el retraso de extracción por profundidad. 3 es el estándar probado en campo . La mayoría de los modelos de lixiviación no necesitarán ajustar este número. Opencontour/Forte puede proporcionar más definición e investigación si así lo solicita. |
Drenaje
| Entradas (Input) | Definición |
|---|---|
| Closure | Fecha para aplicar la lógica de cierre permanente. Opencontour/Forte puede proporcionar más detalles de la lógica de cierre. |
| Discharge Flow Rate | Caudal a la instalación de tratamiento aplicado en la fecha de cierre. Opencontour/Forte puede proporcionar más detalles de la lógica de cierre. |
Write State
Esta característica permite al usuario ejecutar el modelo utilizando Write State, es decir, hasta un cierto punto en el tiempo, luego hacer una pausa. Cuando un modelo se ejecuta en una marca de tiempo específica ("Write State"), todos los parámetros de bloque se almacenan para que las ejecuciones simultáneas comiencen a partir de esa fecha. Esta característica se puede utilizar al combinar datos de apilamiento históricos y pronosticados, o al ejecutar iteraciones después de una fecha especificada determinada.
El usuario puede guardar todas las entradas en cualquier momento durante el proyecto. Sin embargo, recomendamos que si se ha utilizado el ("Write State"), o si se actualiza alguna entrada y difiere de la configuración original del proyecto, el usuario exporte el archivo .json y lo guarde. También recomendamos discutir cómo nombrar y guardar estos archivos con su equipo antes de guardar y cargar la información actualizada.
Esta funcionalidad hace las siguientes suposiciones:
- El usuario ha pasado por el módulo de apilamiento hasta la finalización,
- El usuario ha escrito las propiedades lt y on en la capa del modelo.
Para confirmar que esto se ha hecho, seleccione el modelo en el menú desplegable de la etiqueta y seleccione en la propiedad. La información que se muestra en la ventana del proyecto confirmará el número de veces que la columna del modelo específico recibirá la solución a lo largo de la ejecución del modelo.
El usuario puede guardar todas las entradas en cualquier momento durante el proyecto. Sin embargo, se recomienda que si se utiliza el Write State, o si alguna entrada se actualiza y difiere de la configuración original del proyecto, el usuario exporta el archivo .json y lo guarda.
También recomendamos que analice cómo nombrar y guardar estos archivos con su equipo antes de guardar y cargar información actualizada.
11.4.2 Sistemas
Contiene cualquier dato almacenado como una matriz (datos de series temporales), ya sea clima, tenor o flujos estériles. Muestra cada 'icono' (Planta, estanque o Lixiviación) agregado a la capa schedule y cualquier dato utilizado en el modelo desde ese icono.
| Sistemas | Nombre del sistema (lixiviación, estanque, planta) |
|---|---|
| Data | Encabezados importados de un .csv de series temporales (leaching_I, unleaching_I, unloaded_I, barren_flow barren_tenor) |
| Ranges | Fechas mínimas/máximas de los datos del sistema |
| Dropdown | Puede ver los datos de varios sistemas a través de un gráfico |
Algunos proyectos tendrán datos climáticos. Si este es el caso de su proyecto, revise los siguientes pasos; de lo contrario, continúe con el paso 7.5.
Adición de datos climáticos
Opencontour recomienda el siguiente encabezado de columna y formato al crear un archivo CSV de propiedades climáticas.
Todas las entradas que no sean la fecha deberán definirse como métricas o imperiales.
| Unidades de medida | Unidades |
|---|---|
| Métrico | milímetros/día |
| Imperial | pulgadas/día |
Para importar los datos climáticos del proyecto:
- Seleccione la capa schedule, luego la herramienta (Schedule tool) y, a continuación, agregar lixiviación (add leach). Haga clic en la ventana del proyecto. Aparecerá un icono nuevo en la ventana del proyecto. Haga clic en él para ver sus propiedades.
- Desde la ventana Propiedades, cargará el CSV o actualizará manualmente la información.
11.4.3 Cinética de extracción
Contiene las curvas de extracción para cada tipo de mineral (ow) que muestran la velocidad de extracción para cada tipo de mineral. La designación de ow para cada bloque colocado estará asociada con el Plan de Mina. El usuario puede agregar las ecuaciones de extracción aquí. Los valores se agregan manualmente a cada ow. Se pueden agregar nuevos tipos de mineral en la ventana de texto. La propiedad Designación (Ore Type Designation ) de tipo de mineral debe estar asociada con el ow del plano de mina para conectar las curvas a los bloques dentro del modelo.
| Nombre | Definición |
|---|---|
| Name Dropdown | Escriba un nombre para agregar una curva de extracción |
| Ultimate | El valor final de extracción para ese tipo de mineral, basado en datos de prueba metalúrgica. |
| a | Un factor de velocidad para la ecuación de extracción, basado en datos de prueba metalúrgica. Opencontour/Forte puede proporcionar herramientas para crear estas ecuaciones basadas en datos de prueba. |
| b | Un factor de velocidad para la ecuación de extracción, basado en datos de prueba metalúrgica. Opencontour/Forte puede proporcionar herramientas para crear estas ecuaciones basadas en datos de prueba. |
| Ore Type Designation | Esta propiedad (debe ser un número) coincidirá con la propiedad 'ow' del Plan de Mina para correlacionar las curvas de extracción. |
Una vez que todas las entradas estén en su lugar, guarde todas las entradas de extracción de mineral. Seleccione Guardar y exportar el nuevo archivo json. Una vez más, recomendamos discutir con su equipo el proceso de cómo nombrar y guardar estos archivos antes de guardarlos, y cargar información actualizada. Ahora debería poder cargar el nuevo archivo en su proyecto utilizando la función Cargar dentro del menú Cinética de extracción.
Nota: Al guardar, guardará toda la información del menú del modelo de lixiviación en este punto y no solo la cinética de entrada.
Todos los gráficos se pueden actualizar para adaptarse a las necesidades del usuario. Opencontour permite modificaciones más simples dentro del Software o editando datos utilizando El software en la nube de terceros Plotly.
11.4.4 Solución (Solution)
En esta pestaña encontrarás entradas que pueden cambiar de bloque a bloque o a lo largo del tiempo.
| Nombre | Definición |
|---|---|
| ltp | Tipo de lixiviación. Se utiliza para agrupar bloques y asignar propiedades específicas (histórico vs pronóstico, diferentes contenidos de humedad inicial, ROM vs Crush, tarifas de aplicación aplicadas, etc. ). |
| imc | Moisture Content inicial de un bloque en formato decimal (por ejemplo, 0,05 para un contenido de humedad inicial del 5%). |
| r_ar | Tasa de aplicación de referencia (L/m2/hr o gpm) |
| ar | Tasa de aplicación (L/m2/hr o gpm). |
| ar_v | Aplicación Rate Variance, que se usa cuando la casilla de verificación Modify Application Rate está marcada y es el porcentaje que la tasa de la aplicación puede cambiar en formato decimal (por ejemplo, 0.3 es una varianza del 30%). |
| outfl | Asigne dónde el pad drena a lo largo del tiempo, según los días de lixiviación de cada bloque. |
| infl | Asigne dónde el pad recibe la solución a lo largo del tiempo, en función de los días de lixiviación de cada bloque. |
| Escribe propiedades a CutterResult basado en 'ltp' | Escribe la información de la propiedad de la tabla en cada CutterResult agrupada por 'ltp'. |
El primer paso es asignar valores manuales a: ltp, imc, r_ar, ar y ar_v (Los valores ar_v solo se pueden introducir cuando se marca Modificar tasa de aplicación Modify Application Rate).
Al asignar el valor al ltp, recuerde que este número (s) es exclusivo y no está relacionado con el número de designación dado a su planta o estanque. Por ejemplo, 1 = Rom, 2 = Triturado (crushed)
La operación típica del modelo tendrá marcada la opción modificar tasa de aplicación (Modify Application Rate). Una vez que se alcanza el incremento de planta y se cumple el caudal objetivo (Q_tar), la tasa de aplicación variará dentro de los límites del ar_v y el caudal de la planta se mantendrá constante. Q_tar y las propiedades de designación se establecen dentro del icono de la planta.
Cuando se enumeran todas estas entradas, asegúrese de "Escribir propiedades en CutterResult según ltp" haciendo clic en el botón asociado.
Ahora asigne sus salidas y entradas. Para cada columna y fila, seleccione "Asignar" (assign).
11.4.5 Salidas (Outflows)
Antes de comenzar a actualizar las entradas para las salidas de soluciones, asegúrese de comprobar la designación. Si su proyecto tiene más de una planta o poza, y diferentes líneas de tiempo, se le pedirá que agregue filas. Ejemplo:
| Fecha de inicio (número de días) | Fecha de finalización (número de días) |
|---|---|
| 90 | 119 |
| 60 | 89 |
| 30 | 59 |
| 0 | 29 |
11.4.6 Flujos (Inflows)
Antes de comenzar a actualizar las entradas para las entradas de soluciones, asegúrese de comprobar la designación. Si su proyecto tiene más de una planta o estanque, y diferentes plazos, se le pedirá que agregue filas. Q_tar (Q_target) solo se puede actualizar en las Propiedades de cada planta o estanque. Si necesita editar esta entrada, cierre esta ventana, vuelva a la ventana del proyecto y haga doble clic en el icono de la planta o del estanque, o seleccione la herramienta Propiedades en la barra de herramientas. Ejemplo:
| Fecha de inicio (número de días) | Fecha de finalización (número de días) |
|---|---|
| 90 | 119 |
| 60 | 89 |
| 30 | 59 |
| 0 | 29 |
Si su proyecto tiene más de un ltp, entonces la suma de ambos flujos de entrada (1 y 2) es lo que el proyecto está apuntando a la suma de ambos ejecutándose al mismo tiempo, en las unidades designadas para todo el pad.
Ahora es el momento de escribir estas propiedades en el CutterResult basado en ltp" seleccionando este icono. A continuación, Guardar.
11.5 Ejecución del modelo de recuperación de lixiviación en leach pad
Si se han completado todos los pasos y se han actualizado todas las propiedades de capas de soluciones (Solutions Layers Properties ) que contienen propiedades on y lt, ahora está listo para ejecutar el modelo.
Mientras esté en el modelo de recuperación de lixiviación en pilas, puede ejecutar el modelo desde cualquier pestaña.
11.6 Uso de la función Write State y lectura para modelos más grandes
Antes de considerar agregar más datos de pronóstico, se recomienda que el ingeniero se tome el tiempo para calibrar el modelo para que sus valores se acerquen lo más posible a los reales que su alcance requiera.
Algunos proyectos requerirán que se agreguen datos adicionales a un modelo grande existente. Esta adición podría ser una actualización de apilamiento de lixiviación real mensual o semanal o puede ser un plan de apilamiento pronosticado. Cuando un modelo se ejecuta a una determinada marca de tiempo ("Write State"), todos los parámetros de bloque se almacenan para que las ejecuciones simultáneas comiencen a partir de esa fecha. Ahora describiremos los pasos necesarios para agregar los datos al modelo.
-
Ejecute el modelo existente utilizando la función "Write State": Una vez completada la calibración, determine la última fecha para la que desea ejecutar su modelo, con el 'Write State' marcado, ejecute el modelo (tenga en cuenta que esta fecha será la fecha de inicio de este archivo, en lugar de la primera fecha ‘pm’).
La casilla de verificación “Write State” guarda automáticamente el grupo de modelos de lixiviación. Este archivo se puede encontrar en "Archivo, Guardar menú desplegable".
Esto guardará el "estado" (state) de cada CutterResult al final de la ejecución del modelo. Esto incluye propiedades como flujo de salida, días de lixiviación, metal extraíble restante, metal acumulado realizado, flujos acumulativos aplicados / drenaje. Además, se guardará el archivo .JSON.
El Grupo de Modelos de Lixiviación es la nueva Base y escrito como tal, no es el resultado base. El usuario ahora puede usar este nuevo archivo para trabajos futuros, como el apilamiento de pronósticos cuando necesita crear más rellenos o puede continuar trabajando en esta instancia creando más contornos de relleno.
2. Ya sea trabajando en esta instancia, o en una separada, el usuario ahora tendrá que verificar el "Read" State para decirle al modelo que retome donde lo dejó nuestra última ejecución de modelo. Observe que cuando ejecutamos el modelo con el "Read State" marcado, aparece una línea roja punteada que marca la fecha del último modelo de ejecución. Además, mostramos las fechas en que el modelo se ejecutó por última vez en la parte superior de la pantalla (desde y hacia).
En resumen, para iniciar cualquier ejecución de modelo donde se leerá o escribirá el guardado, primero debemos comenzar marcando el "Read State", el usuario puede continuar trabajando en su archivo o trabajar en el archivo de grupo guardado más tarde. Ahora que se ha ejecutado este modelo base, el usuario solo tendrá que marcar "Estado de lectura" para continuar donde lo dejó el último modelo. El usuario también puede usar ambas casillas de verificación juntas para anexar continuamente los valores informados.
11.7 Combinación de datos históricos con actualizaciones futuras (pronóstico)
El usuario requerirá seguir los pasos descritos en el Capítulo 7.6, incluido el guardado del archivo en grupo.JSON.
Crear un nuevo plan de apilamiento: se puede crear un plan de apilamiento a partir de la fecha de "Write/Read State" como un archivo independiente. Esto puede ser una actualización histórica mensual, o puede ser un apilamiento estimado.
1. Utilice el nuevo archivo .json de grupo del modelo más grande como la topografía base inicial para este nuevo apilamiento para que no hayan brechas.
2. Siga las instrucciones de apilamiento histórico o de estimado.
3. Guarde este archivo con descripciones, por ejemplo, [YYMMDD]_pad1_2021stacking_all.json
4. Guarde la capa CutterResult como un archivo independiente para la importación, no como el modelo más grande. Guarde este archivo con descripciones, por ejemplo: v_pad1_202_stacking_cr.json
5. Guarde las celdas de la solución como un archivo independiente:[YYMMDD]_pad1_202 1_stacking_solution.json
11.7.1 Importe el archivo CutterResult en el modelo existente:
Abra una nueva sesión de proyecto (nueva pestaña), arrastre y suelte el archivo.json recién creado con la descripción write_state_all.json.
El nuevo archivo CutterResult, con datos actuales o de previsión, deberá anexarse al archivo BasellAll siguiendo estos pasos:
Abra el módulo de apilamiento de lixiviación en leach pad (menú de herramientas) Pestaña Misc - Anexar resultado del cortador - Elija archivo
La función Append anulará cualquier bloque de la capa CutterResult existente con cualquier bloque nuevo. Esto evita tener formas duplicadas de CutterResult. El nuevo conjunto de datos de apilamiento (CutterResult) se anexará al modelo existente. Además, también agregará el 'cut_fill_num' de CutterResult importado al máximo 'cut_fill_num' del conjunto de datos de CutterResult existente.
Utilice la herramienta Script para rellenar la propiedad 'ltp' en la capa CutterResult. Después de hacer clic en Aceptar, salga de la ventana. Al rellenar el Mineplan se asigna automáticamente un valor 'ltp' de 1. Dependiendo de cómo se configure la previsión futura, este valor se puede manipular a discreción del usuario.
ltp en la herramienta Script
Agregue las nuevas celdas de solución arrastrando el nuevo archivo de solución a la capa de solución.
Vuelva al menú de herramientas, seleccione módulo de modelo de lixiviación en leach pad y, en la pestaña Progress, ejecute la función "Actualizar solución (Update Solution)" para rellenar la capa del modelo con los polígonos de solución más recientes.
En este momento, el usuario puede agregar (calcular) el tiempo de percolación a los polígonos de solución que existen en la capa de solución. Si el proyecto tiene bloques CutterResult que tienen propiedades on y lt escritas en ellos a través de un script, seleccionando la funcionalidad agregar tiempo de percolación junto con 'Actualizar solución',(Update Solution) se agregarán los días que se tarden en irrumpir en la propiedad lt. El cálculo del tiempo de interrupción se basa en las entradas globales de su proyecto y la distancia al revestimiento.
Botón Breakthrough Time
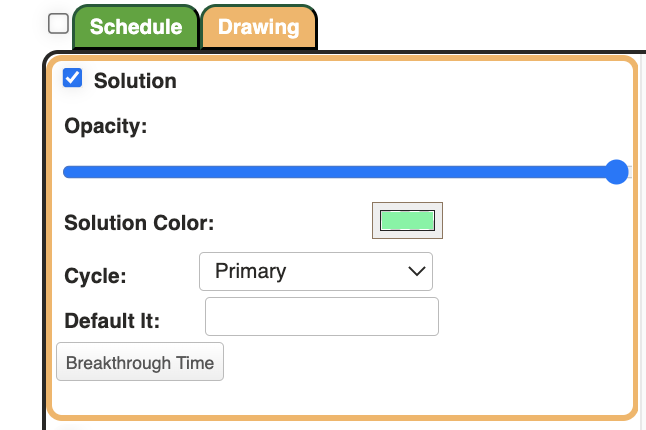
11.7.2 Read State
El usuario verá una vez que el write_state_all.json se arrastre a la ventana del proyecto, se comprobará el Read State.
Lo que esto significa es que el Modelo ahora leerá el último "# de días", especificado en duración de ejecución (Run Duration), del modelo que ya hemos ejecutado.
En entradas globales, el usuario ahora verá una nueva fecha de inicio: el día después de ejecutar el último modelo.
11.7.3 Revisar el modelo actualizado
El usuario requerirá abrir la pestaña de salidas (Outputs), desde nuestro modelo de recuperación de lixiviación en pilas. Luego, asigne los datos que se revisarán a la barra de datos y ejecute el modelo.
La línea roja del tablero indica que todo lo anterior a la línea roja ya ha tenido el modelo ejecutado. Ahora, estamos comenzando desde la línea roja del tablero en adelante.
Después de ejecutar el modelo (para obtener más información sobre cómo ejecutar el modelo, vaya al Capítulo 7.7 ), los nuevos datos serán acumulativos para todo el panel. Los datos se pueden exportar a Excel para su posterior análisis.
Este proceso se repetirá cada vez que el usuario desee actualizar su modelo con información real y de previsión.
11.8 Propiedades del modelo de recuperación CutterResult
| Nombre | Resumen |
|---|---|
| midx | Coordenada X del punto central de bloque (por ejemplo, 6501625) |
| midy | Coordenada Y del punto central de bloque (por ejemplo, 2182875) |
| midz | Elevación de bloques (por ejemplo, 2930) |
| z | Elevación del bloque (por ejemplo, 2930 = midz) |
| type | Qué tipo de forma es (siempre se rellenará para el modelado) |
| pn | Propiedad utilizada para ordenar, combinación de pn_gid_z (por ejemplo, S3_L1_C6_5x6_2930_) |
| gy | Coordenada de cuadrícula numerada Y (ej. 7) |
| gx | Coordenada de cuadrícula numerada X (ej. 5) |
| gid | Propiedad única para cada bloque, una combinación de gx y gy (ej. 5x7) |
| seq | Después de ordenar, asignamos números 1 – n donde n representa el número de bloques (por ejemplo, 11450) |
| swell | Utilizado para el cálculo de toneladas (debe ser 1 para la mayoría de los modelos que no ocupan Opencontour) |
| on | Fecha en que el bloque recibe solución, utilizada con 'lt' para decidir cuándo gira |
| la | Tipo de capa (por ejemplo, cr, insignificante) |
| lt | Ciclo de lixiviación, Días de recepción de la solución (ej. 75) |
| dens | Densidad de bloques, utilizada en el cálculo de toneladas (ex. 0,057) |
| tns | Toneladas de bloque = vol x densidad (ex. 1425) |
| area | Área del bloque = ancho x alto (por ejemplo, 2500,00) |
| vol | Volumen del bloque = área x altura del banco (por ejemplo, 25000) |
| fi | Nombre de fase del bloque, asignado a través de la capa Relleno (por ejemplo, S3_L1_C6) |
| cut_fill_num | Número de relleno del menú de capas, (ej. 7) |
| dir | Dirección de apilamiento del pad, asignada a través del menú de capas (ej. 180) |
| ow_min | Tipo de mineral («ow») valor mínimo (ej. 0,5) |
| ow_max | Tipo de tipo de mineral («ow») valor máximo (ej. 10000) |
| au | Ley de oro en bloque (ex. 0.027056889) |
| ag | Ley de plata en bloque (ex. 0.3522071110000001) |
| imc | Contenido inicial de humedad (por ejemplo, 0,08) |
| sseq | Secuencia de apilamiento, utilizada con dirección (ej. 3797) |
| ow | Tipo de mineral, importado de minplan (ex. 70) |
| pm | Fecha que se colocó el bloque (ej. 44884) |
| ltp | Tipo de lixiviación (ex. 3) |
| ultimate | Último de la curva de extracción (por ejemplo, 0,699999988079071_) |
| on_seq | Número ordenado utilizado para activar/desactivar bloques de varianza (ej. 9371) |
| aum1 | Metal colocado inicialmente (ex. 1199.5086669921876) |
| aurp1 | Bloque de metal recuperable colocado al principio del modelo (ex. 839.6558837890625) |
| aur1 | Bloque metálico restante al principio del modelo (ex. 458.4161071777344) |
| auer1 | Bloque de metal extraíble que queda al principio del modelo (ex. 98.5635604858398 |
| aufi1 | Inventario de metales de soluciones de flujo de bloques al inicio del modelo (ej. 0) |
| ausi1 | Bloque de solución estancada inventario de metal al inicio del modelo (ex. 0.30331748) |
| aux1 | Extracción de bloques inicio del modelo (por ejemplo, 0,6178300380706787) |
| aum2 | Metal colocado al final del tiempo = aum1 (ex. 1199.5086669921876) |
| aurp2 | Bloque de metal recuperable colocado al final del modelo = aurp1 (ex. 839.6558837890625) |
| aur2 | Metal restante al final de la ejecución del modelo (ex 58.4161071777344) |
| auer2 | Total de metal extraíble restante al final del modelo (ex. 98.56356048583985) |
| aufi2 | Metal de solución fluida al final del modelo (ej. 0) |
| ausi2 | Metal de solución estancada al final del modelo (ex. 0.30331748723983767) |
| aux2 | % de metal extraído al final de la ejecución del modelo (por ejemplo, 0,6178300380706787) |
| flow_out_bottom | Flujo de salida de la parte inferior del bloque al final de la ejecución del modelo |
| days_leaching | Número de días de lixiviación, incluye cálculos de punto de corte y pendiente |
| moisture_content | Contenido de humedad del último día de ejecución del modelo (por ejemplo, 0,13926574587821) |
| r_ar | Tasa de aplicación de referencia (ex. 0,005) |
| pm2 | Fecha colocada en el bloque anterior (por ejemplo, 47785) |
| pm3 | Diferencia entre la fecha colocada arriba y la fecha de los bloques actuales (por ejemplo, 12) |
11.9 Funciones Agregadas y Resulatados del Modelo de Recuperación
N/A indica que no se aplica ningún resultado y que no se debe mostrar nada para ese resultado y agregación.
-
Delta(t) = (día + 1) – (día)
-
MEV = Month End Value (Valor de fin de mes) (interpolado linealmente, más una curva que un paso a paso) lo que ocurre ahora con la suma mensual de funciones
-
Total (Total) = Suma de Delta(t) a lo largo del período de tiempo
Metal
| Selección de datos | Acumulativo | Diario | Mensual | Semanal |
|---|---|---|---|---|
| Metal_realized(Metal realizado) | Data | Delta(t) | Total | Total |
| Flowing_solution_metal_inventory (Inventario de metales de soluciones en tránsito) | N/A (display daily) | Data | MEV | MEV |
| Stagnant_solution_metal_inventory (Inventario de metales de soluciones estancadas) | N/A (display daily) | Data | MEV | MEV |
| Metal_applied_to_pad (Metal aplicado al pad) | Data | Delta(t) | Total | Total |
| Net_metal_produced (Metal neto producido) | Data | Delta(t) | Total | Total |
| Solution_metal(Solución metálica)N/A (display daily) | Data | MEV | MEV | |
| Total_metal_placed (Total de metal colocado) | Data | Delta(t) | Total | Total |
| Total_recoverable_metal_placed (Total de metal recuperable colocado) | Data | Delta(t) | Total | Total |
| Total_unrecoverable_metal_placed (Total de metal irrecuperable colocado) | Data | Delta(t) | Total | Total |
| Total_metal_remaining Total_metal_remaining (Metal total restante) | N/A (display daily) | Data | MEV | MEV |
| Total_extractable_metal_remaining (Total de metal extraíble restante) | N/A (display daily) | Data | MEV | MEV |
Totales de Soluciones
| Selección de datos | Acumulativo | Diario | Mensual | Semanal |
|---|---|---|---|---|
| Leaching Cells (Celdas de lixiviación) | N/A (display daily) | Data | Promedio | Promedio |
| Precip_infiltration[gpm] (Infiltración de Precip[gpm]) | N/A | Data | Promedio | Promedio |
| Precip_runoff [gpm] | N/A | Data | Promedio | Promedio |
| Cumulative_precip_infiltration[gal] (Infiltración precipicia acumulada[gal]) | Data | Delta(t) [gal/day] | MEV | MEV |
| Discharge_flow_rate[gpm] (Caudal de descarga[gpm]) | N/A | Data | Promedio | Promedio |
| Cumulative_discharge_flow[gal] (Flujo de descarga acumulativo[gal]) | Data | Delta(t) [gal/day] | MEV | MEV |
| Cumulative_precip_runoff [gal] | Data | Delta(t) [gal/day] | MEV | MEV |
| Active_cells (Células activas) | Data | Delta(t) [cells/day] | Promedio | Promedio |
| Total_blocks (Total de bloques) | Data | Delta(t) [blocks/day] | Total | Total |
| Tns_stacked (Tns apilados) | Data | Delta(t) | Total | Total |
| Solution_inventory[gal] (Inventario de soluciones[gal]) | N/A (display daily) | Data | MEV | MEV |
| Volume_drained[gal] (Inventario de soluciones[gal]) | Data | Delta(t) [gal/day] | MEV | MEV |
| Draining_flow-rate[gpm] (Caudal de drenaje[gpm]) | N/A | Data | Promedio | Promedio |
| Applied_flow_rate[gpm] (Caudal aplicado[gpm]) | N/A | Data | Promedio | Promedio |
| Volume_applied [gal] | Data | Delta(t) [gal/day] | MEV | MEV |
| Flowing_solution_inventory [gal] (Inventario de soluciones fluidas[gal]) | N/A (display daily) | Data | MEV | MEV |
| Stagnant_solution_inventory[gal] (Inventario de soluciones estancado[gal]) | N/A (display daily) | Data | MEV | MEV |
| Cumulative_precipitaion [gal] | Data | Delta(t) [gal/day] | MEV | MEV |
| Average_precipitation_rate[gpm/ft2] (Precipitación acumulada[gpm/ft^2]) | N/A (display daily) | Data | Promedio | Promedio |
| Design_num_Blocks(Diseño Bloques) | N/A (display daily) | Data | Promedio | Promedio |